THE REGEX KING
Jeff Sisson's blog (email me)
talk2html
I like a live event where the format is people riffing, and try to attend these when I can. It’s also remarkable that we live in an era with unprecedented access to recordings of these types of live events: I’m always seeing or being sent links to a video recording of a presentation, a panel discussion, or a video version of a podcast.
Unfortunately, the practice of watching or listening to recordings of a talking event has never worked for me: I don’t have a car commute, I don’t use headphones on the train or the bike, and I’m not able to listen to recordings of people talking while I’m on the clock at work. When I do have time at home available for durational media, I’m trying to listen to music, catch a basketball game, watch a movie, or watch braindead TV, in that order.
I do, however, have plenty of other time to read, and this has become even more true as my kid has learned to read and we’ve unlocked “everyone in the family is reading at the same time”. I’d always wondered whether I might be able to catch more of these live event recordings if I could timeshift them from durational media to written media.
To gather some data on this hypothesis, I made a command line tool called talk2html. This tool wraps the excellent yt-dlp command line tool to download videos from YouTube, and post-process them as a filmstrip of images from the video with text presented along-side the recording’s images.
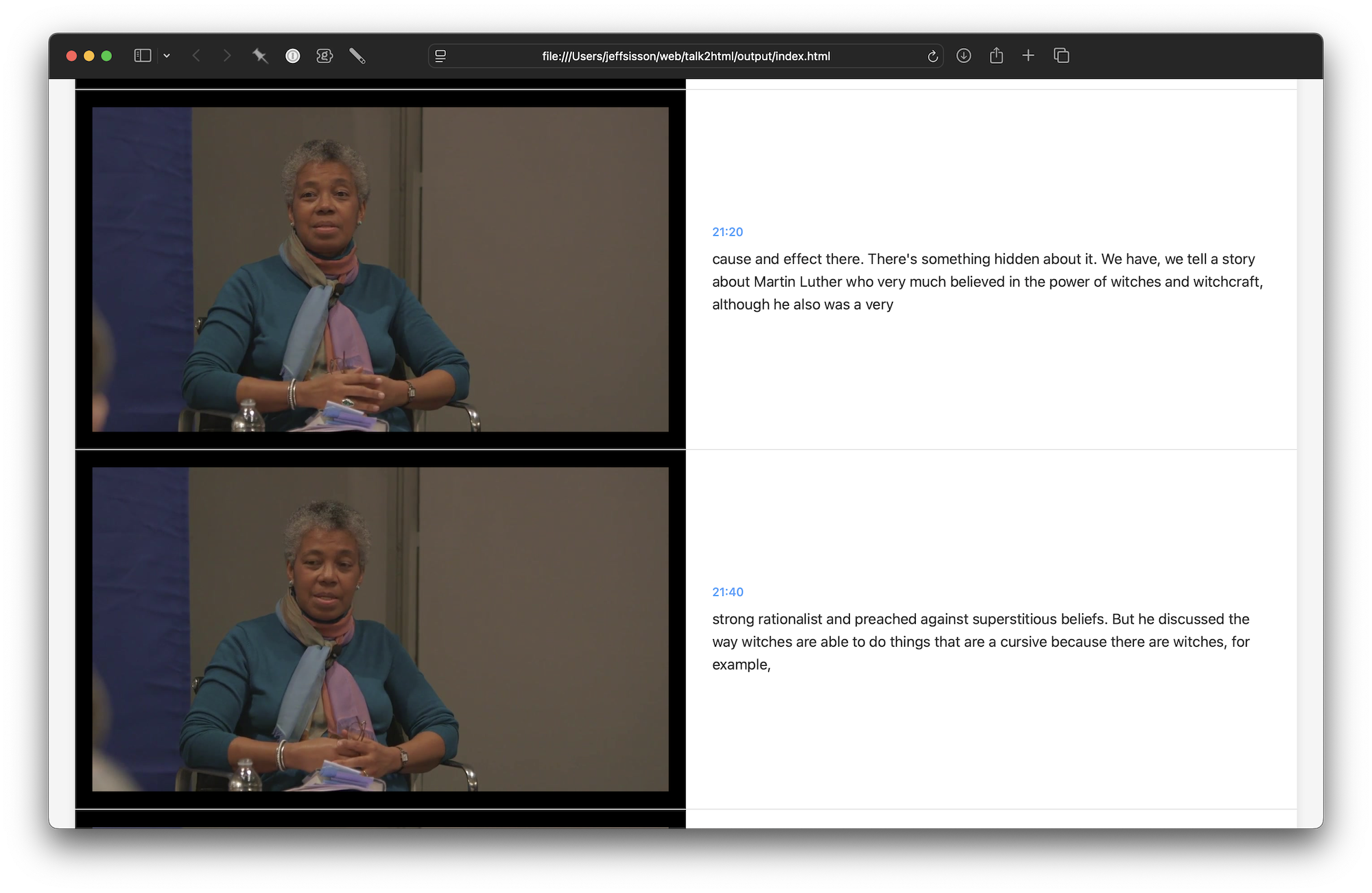
talk2html.I’m not yet sure if “reading” a talk/panel/discussion/podcast instead of watching it loses something in translation. I just tried “reading” this great conversation between Barbara Fields and Ta-Nehisi Coates; it was cool to be able to read the whole thing where I almost certainly would not have otherwise had time to watch it at all. I suspect this tool will help me to move recordings like these off of my “to watch” list.
But I still found myself jumping to specific parts of the recording where the automatic transcript wasn’t good, or where it was clear that some meaning was being lost as written vs. as spoken. Which is maybe just to say: I do not recommend talk2html for use by grindset guys who are looking to try to pound media (written or durational) like nutraceuticals in a functional smoothie.
On the other hand, I did use talk2html to “read” a conference talk about local-first software, which I won’t name. That talk turned out to be kind of low information and vaporware to my taste, and I was glad to not have spent an hour with it.
Interview: Julien Minet - OpenArdenneMap
Great interview with the maintainer of a region-specific OpenStreetMap style called “OpenArdenneMap”, that’s been optimized for hiking in a specific region in the world (the Ardennes) while still being usable and forkable for use elsewhere.
I found this interview while researching tools I could use to make a print map of the neighborhood for my son (I ended up using QGIS). I’m inspired by this idea of region-specific cartography and site-specific digital tools:
To come back to OpenArdenneMap, as its name suggests, it’s designed for one region in particular: the Ardennes. A friend once asked me to produce a map of Brittany using OpenArdenneMap and then complained that the sea didn’t appear. Of course, there’s no sea in the Ardennes. Far from any chauvinism or nationalism, the idea is to create a rendering specific to a region, with its own characteristics and particular objects, and of course this can evolve over time. For example, there is a specific rendering in OpenArdenneMap for Christmas tree plantations, because they cover a large area in the Ardennes, perhaps 10% of the agricultural area. But this is a recent development, and it’s possible that in a few decades there won’t be any left.
One disadvantage of web maps is that we are witnessing a standardisation of styles, with styles that can be designed for a Californian environment and then applied in Europe: this makes no sense. Each region has its own geographical richness, the result of the evolution of the natural landscapes inhabited by the human communities who have lived there. And so each region is entitled to its own styles, which highlight its characteristics.
Utopian XHTML at the SEC
I’ve been working on a project that was riffed into existence by friends John, Olov, and Nora at Grand Morelos: it’s called Labor Leverage. It’s loosely based on workshops John and our coworker Stacy Cowley have run previously, where they share with other unions how to research employer finances in order to build power at the bargaining table. Big public companies are required to report data to the SEC as part of that institution’s purpose in stabilizing public markets, and it turns out many of the same data are useful to reveal how your employer and its executives actually spend its money. Profits, stock buybacks, executive salaries and stock compensation, all available in SEC data made available to the public!
The format of this data is interesting: companies upload their data to the SEC’s EDGAR (Electronic Data Gathering, Analysis, and Retrieval) system. The API is beautiful, and is barely even an API at all: it’s “just” HTML files, uploaded at predictable paths. Specifically, it’s XHTML, the older and crankier subset of today’s HTML that was meant to validate against a strict XML syntax. Companies embed snippets of another XML flavor, iXBRL (eXtensible Business Reporting Language) inside of the HTML, so that you can have a report that looks like a webpage with tabular profit and loss tables, buried within which are machine-readable XML tags describing key accounting figures as structured data.
Many of the tags encode dry, Generally Accepted Accounting Principles (GAAP) data like us-gaap:NetIncomeLoss, us-gaap:StockRepurchasedDuringPeriodValue, or us-gaap:CashCashEquivalentsRestrictedCashAndRestrictedCashEquivalents. Maybe more interesting are the data that companies are required to report by the government, but which don’t use machine-readible XML tags because they are not legally required to do so. These include data that’s absolutely relevant to unions like the one I belong to, such as the number of total employees, or the CEO Pay Ratio disclosures required by law following the 2008 financial crisis. These data are written as prose in the report, and so extracting them from the text requires the use of cruder text matching techniques. It’s tempting to picture a regulatory regime where financial data relevant to workers also had legally-mandated, machine-readable XML tags!
Compared to the freewheeling, single page app oriented ecosystem of today’s HTML5, reading iXBRL-flavored XHTML is like discovering an exotic dialect of a language that’s been cut off from its parent for so long that it’s had to invent grammars and styles of its own. <FONT> is everywhere. All elements have 20-30 inline style definitions in lieu of CSS. When I was scraping this data, I was surprised to find that that all the 10,000 or so companies clock in with 29GB worth of HTML. The reason the dataset is that large is because each document tends to have extreme HTML energy: the biggest document—a DEF-14A filing from Vaso Corporation— weighs in at 36MB, in part because there are long sections where every single character is wrapped in a distinct font tag (!).
I remember writing HTML in the era where the trend was towards making sure your HTML passed strict XML validation, like these documents do; there were hundreds of tools that would feed your HTML thru a validator and scold you for your HTML sins. At some point things trended away from XML generally, and away from HTML validation specifically, but it’s kind of beautiful that the backstop of a powerful government agency has left an oasis where XML validation and truly semantic XML elements still reign. Matt Levine recently wrote about how there are even companies whose entire business is to “EDGARize” companies' HTML:
If you are an SEC lawyer — if you look at this system from a reasonable level of abstraction — then the way Edgar works is (1) a company sends its material nonpublic information to Edgar and (2) Edgar immediately makes it public. Information passes through the system for an infinitesimal time; the filing system does not hold on to a bunch of secret corporate information in its servers. Edgar is a publication interface, not a database of company secrets.
But of course if you are an Edgar typesetter, you do not look at this system from that level of abstraction. You deal with the actual system, which operates at a not-at-all-infinitesimal time scale. You are like “man, this stuff sure takes a long time to typeset.” And there are trades there.
It’s absolutely someone’s dream to run a business helping companies to write XML-compliant HTML, with a sideline making millions from illegal stock market information you’ve read in the XML-compliant HTML!
Re-uploading Unix Time
In 2016 I was inspired to run a series of DIY workshops on the command line and the Unix philosophy generally. I’d been chatting with a handful of friends about interest in learning more about the history of Unix and non-graphical interfaces. I chose the name “Unix Time” as a tribute to the time convention of the same name, and we met for several months in Red Hook, Brooklyn at Beam Center.
I recall these workshops having been pretty fun: a nice group with both technical and non-technical people showed up, and we worked thru some command line and Unix basics (how do I execute a command? what does it look like to setup my shell?) all the way thru to headier parts of the Unix ecosystem like wall, talk, and telnet.
I can’t remember if this was Allen or Sam’s idea but at some point the group co-authored a bash script to produce On Kawara’s Date Paintings from the command line! Here’s that script, for perpituity:
i=0
while read d; do
i=$((i+1))
echo $d | convert \
-size 800x500 \
xc:black \
-pointsize 60 \
-fill white \
-gravity center \
-font /usr/share/fonts/truetype/futura/futura.ttf \
-draw "text 0,0 '$(cat - | tr '[:lower:]' '[:upper:]')'" \
-paint 2 jpg:- > "kawara-${i}.jpg"
done < "${1:-/dev/stdin}"
convert -delay 120 -loop 0 kawara-*.jpg gif:-
Jason mentioned Unix Time at his birthday party recently, and I was inspired to re-upload the syllabus for the Unix Time workshops at unixtime.bigboy.us. This syllabus used to be on a Unix server I’d rented specifically for Unix Time — everyone had their own proper Unix user accounts — but at some point in our telnet explorations, I exposed a telnet server that was immediately hacked and so I had to take the server down.
We continued to meet well beyond this syllabus, although at some point things petered out. I’m hoping this syllabus — while not a complete artifact showing all of the cool things the people in the workshops did — can at least act as a signpost for people with similar interests in the future.
Updating volume pops pro
In 2011, which in retrospect was a gentler computer era, I made a piece of software called Volume Pops Pro which installed custom sounds over the system default “pop” sound you get when you increase or decrease the volume on a Mac computer. There was a Funkmaster Flex inspired explosion sound, and an airhorn sound. It was packaged as a package installer that put the files in the correct place. Fun!
At some point in the past 14 years, the installer stopped working. The MacOS operating system has been hardened: there are parts of the file system protected by something called “system integrity protection (SIP)" which prevents making changes to parts of a Mac’s software, including this little pop sound. They also changed the default setting so that instead of playing a feedback sound by default, it’s inverted and you have to deliberately hold down the shift key to hear a feedback sound. Less fun!
My buddy Jivko has asked year after year for a version of Volume Pops Pro that would work again on modern computers. I recently updated the software to make it work. It was a pain: I had to write a MacOS native app, which requires paying Apple a yearly licensing fee in order to sign applications for direct distribution so that they aren’t flagged as potential malware. Apple maintains an under-documented API for listening to global media key events like volume up and down, and so the app listens to these and plays a custom sound in response. There is no way to suppress the system default feedback you get when pressing the “shift” key, though, so I had to consecrate a new key (control) for temporarily muting the custom Volume Pops sound while changing the volume (this is handy in parties or while playing music loud, where you sometimes don’t want to blast an airhorn). There’s definitely a computing metaphor somewhere in here about how something that used to be complicated (put a file on your computer) has now become quite complicated (install a custom app that listens and overrides keypresses, and pay a huge corporation for the privilege).